「爬蟲」一直是資料擷取領域中一個實用但極具挑戰性的技術。對於技術新手而言,入門門檻高,需要學習眾多前置知識,例如網路協定、HTML 結構、以及各種程式語言函式庫。而對於經驗豐富的開發者來說,爬蟲程式也並非一勞永逸,網站的版面或標籤(tag)一旦更新,原有的程式碼便可能失效,必須耗費時間重新調整。這使得維護爬蟲程式成為一項持續性的工作。
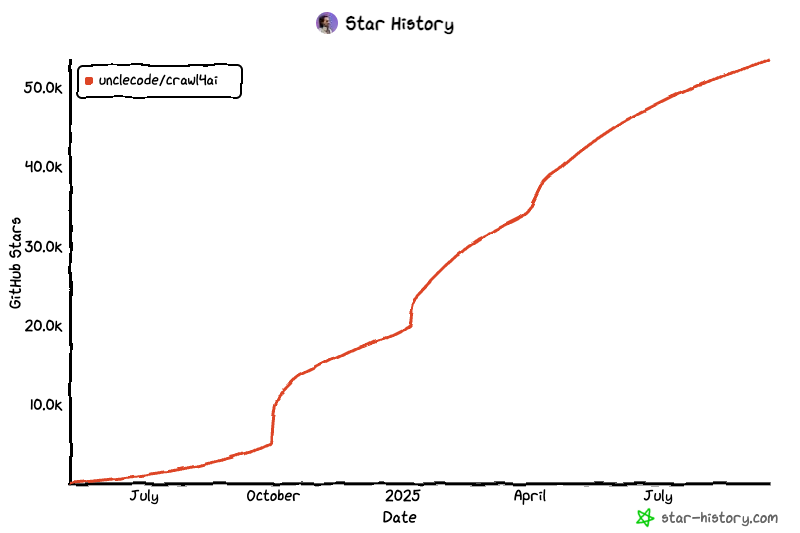
然而,有一項開源專案在 GitHub 上橫空出世,徹底顛覆了這個局面。它利用人工智慧技術,大幅簡化了爬蟲流程。無論你是技術新手還是資深開發者,Crawl4ai 都能讓你更輕鬆地應對爬蟲的各種挑戰。這不僅降低了技術門檻,也提高了程式的穩定性與適應性,讓開發者不再需要擔心網站改版所帶來的程式失效問題。那就是最近很紅的Github Repo - Crawl4ai 。