Google Gemini Live API 運作流程圖
Google Gemini Live API 是一套專為即時互動應用設計的應用程式介面 (API),支援串流對話及多模態輸入與輸出。使用此 API,開發者可以讓應用程式和 Gemini 語言模型進行即時、順暢的互動[1],支援語音輸入、視覺辨識與文字處理等多模態功能,滿足即時互動應用的開發需求。
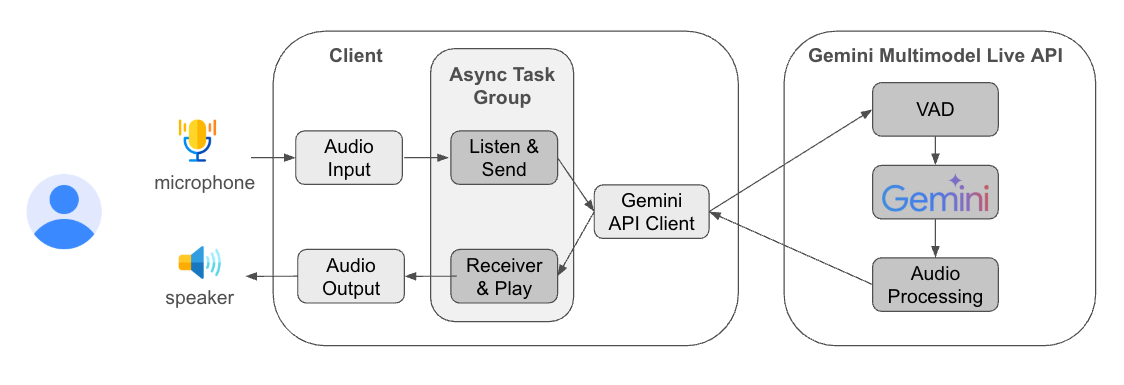
其運作流程如下圖[9]:
【Google Cloud Next'25】Gemini Live API 是什麼?一次搞懂 Google 最新互動技術與商業應用實例

Jan 09
Google Gemini Live API 運作流程圖
Google Gemini Live API 是一套專為即時互動應用設計的應用程式介面 (API),支援串流對話及多模態輸入與輸出。使用此 API,開發者可以讓應用程式和 Gemini 語言模型進行即時、順暢的互動[1],支援語音輸入、視覺辨識與文字處理等多模態功能,滿足即時互動應用的開發需求。
其運作流程如下圖[9]:
支援多模態輸入,包括靜態影像、影片畫面等。透過 Live API 串流傳送視覺內容,讓模型即時辨識環境、文件或場景,並提供對應的文字講解或回答[1][2]。
支援雙向即時對話,用戶可在模型回答途中即時中斷並提出新問題。模型能即時辨識語音中斷信號,停止當前回答並理解新提問,提供更自然的交談模式[2]。
相較於傳統 Gemini API(如 Gemini 1.5 Pro),Gemini Live API 在功能與使用方式上有顯著差異:
結合即時回應、語音辨識、多模態處理與長記憶能力,讓使用者能在對話中獲得更即時、自然的互動回應。
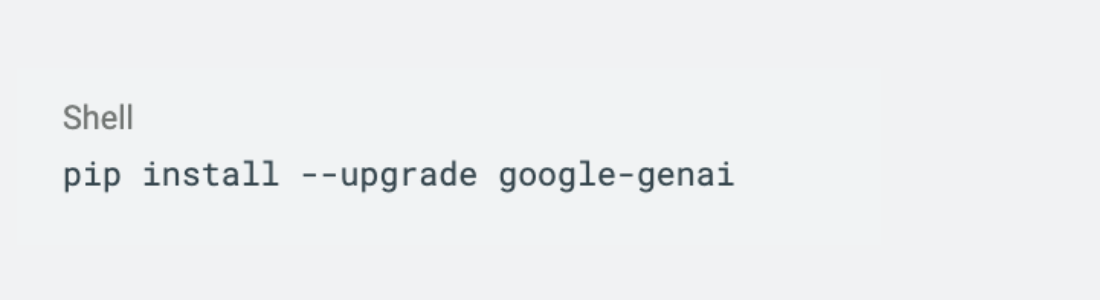
以下是使用 Live API 做文字生成的範例(使用 Python3.9 版本)[8]


Gemini Live API 支援語音、文字與視覺多模態互動,特別適合開發需要即時回應、語音對話與上下文記憶的應用。以下整理出五大實際應用場景:
在多模態與即時互動應用方面,Gemini Live API 相較於 OpenAI GPT-4 Turbo 及 Anthropic Claude 的串流功能,具備以下優勢:
Google 推出 Gemini Live API 是建構未來即時語音與視覺互動平台的關鍵工具。其低延遲串流架構、語音與影像支援、上下文記憶管理等功能,為開發者打造:
參考文件
確認並返回
2025
DEC
29
GPT-5.2 vs. Gemini 3 Pro :全球等級的 AI 模型競爭
2026
JAN
09
什麼是 Agentic AI?五分鐘了解集自主決策、規劃、執行能力於一身的 AI 助手
2026
JAN
08
CloudMile 揭秘!招募 AI 人才看重的 3 項關鍵特質
2026
JAN
08
Model Context Protocol(MCP)是什麼?讓 AI 助理從「說」到「做」
2026
JAN
08
金融業轉型必看!金管會最新 AI 指南與生成式 AI 應用案例
2026
JAN
08
【AI 手把手教學】五分鐘帶你從零創建 Agentspace
2026
JAN
07
什麼是 MSSP?企業資安外包的關鍵解方與雲端資安的未來
2026
JAN
05
什麼是 Agentic AI?五分鐘了解集自主決策、規劃、執行能力於一身的 AI 助手
確認並返回
確認並返回