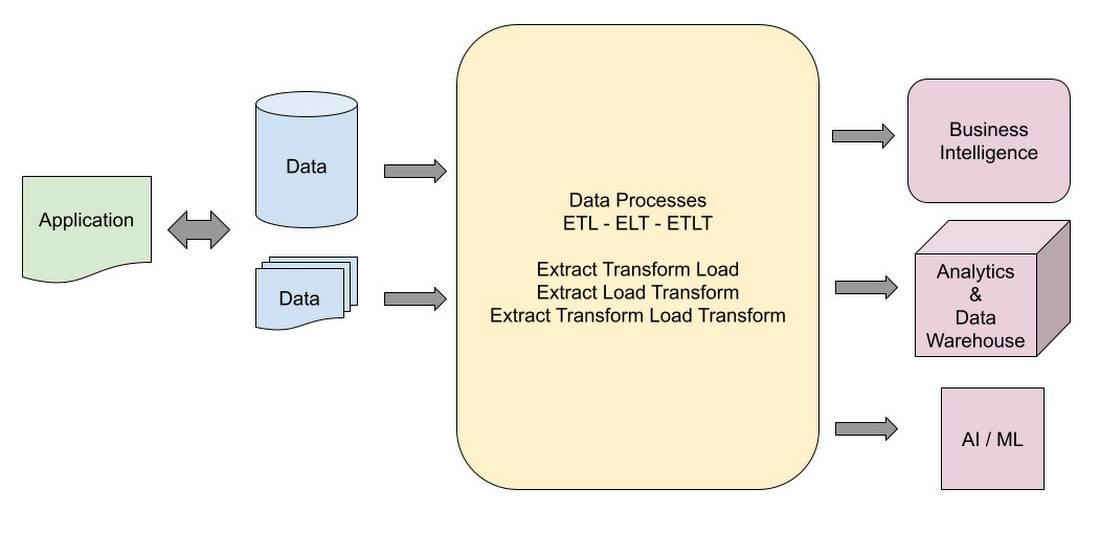
根據 Google 的調查顯示,資料工作者有 45% 的工作時間用於資料前處理,包含轉換和清洗資料。隨著資料量的不斷增長,資料類型、格式和來源的增加以及流量的不確定性也提升了資料處理的複雜度,為資料工作者帶來了全新的挑戰。 有效地處理和管理資料對於企業的成功至關重要。Data Pipeline 可以幫助企業自動化資料處理過程,減少手動錯誤並提高資料品質和處理效率,從而釋放資料工作者,讓他們專注於商業洞察和挖掘市場機會,不必再被束縛於高重複性的工作中。瞭解不同的 Data Pipeline 設計模式和架構類型可以幫助您更好地應對不同的資料處理挑戰,提高您的工作效率和資料處理能力,重新聚焦於創造更好的服務。 本文旨在向您介紹 Data Pipeline 的架構設計概況,您將會學到:
- Data Pipeline 是什麼?
- Data Pipeline 有哪些優勢?
- Data Pipeline 有哪些組成要素?
- Data Pipeline 的類型在設計
- Data Pipeline 的過程中,您需要...
- 在 Google Cloud 上的 Data Pipeline 架構實例