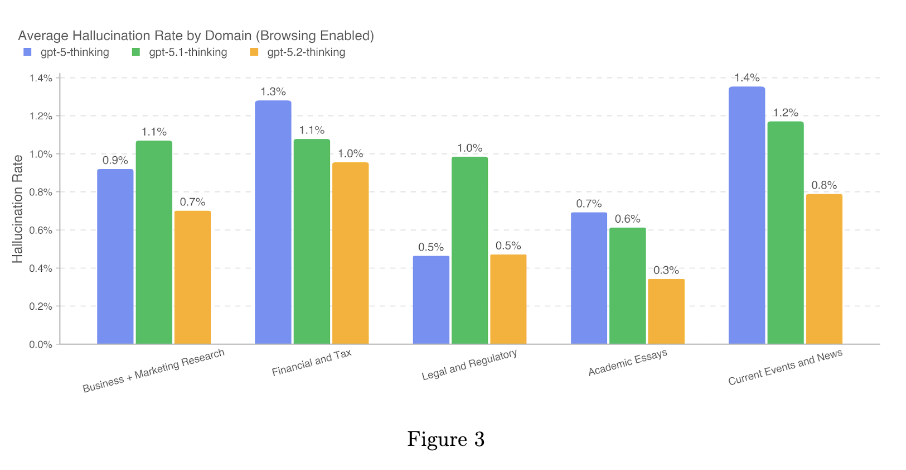
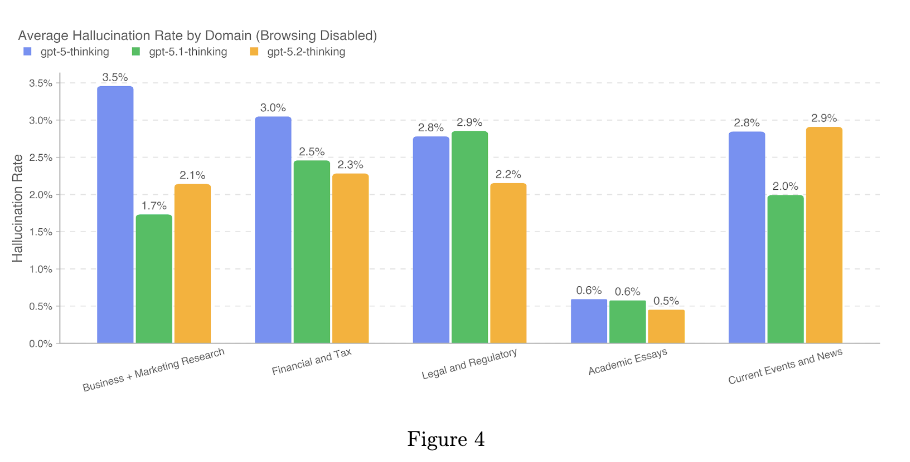
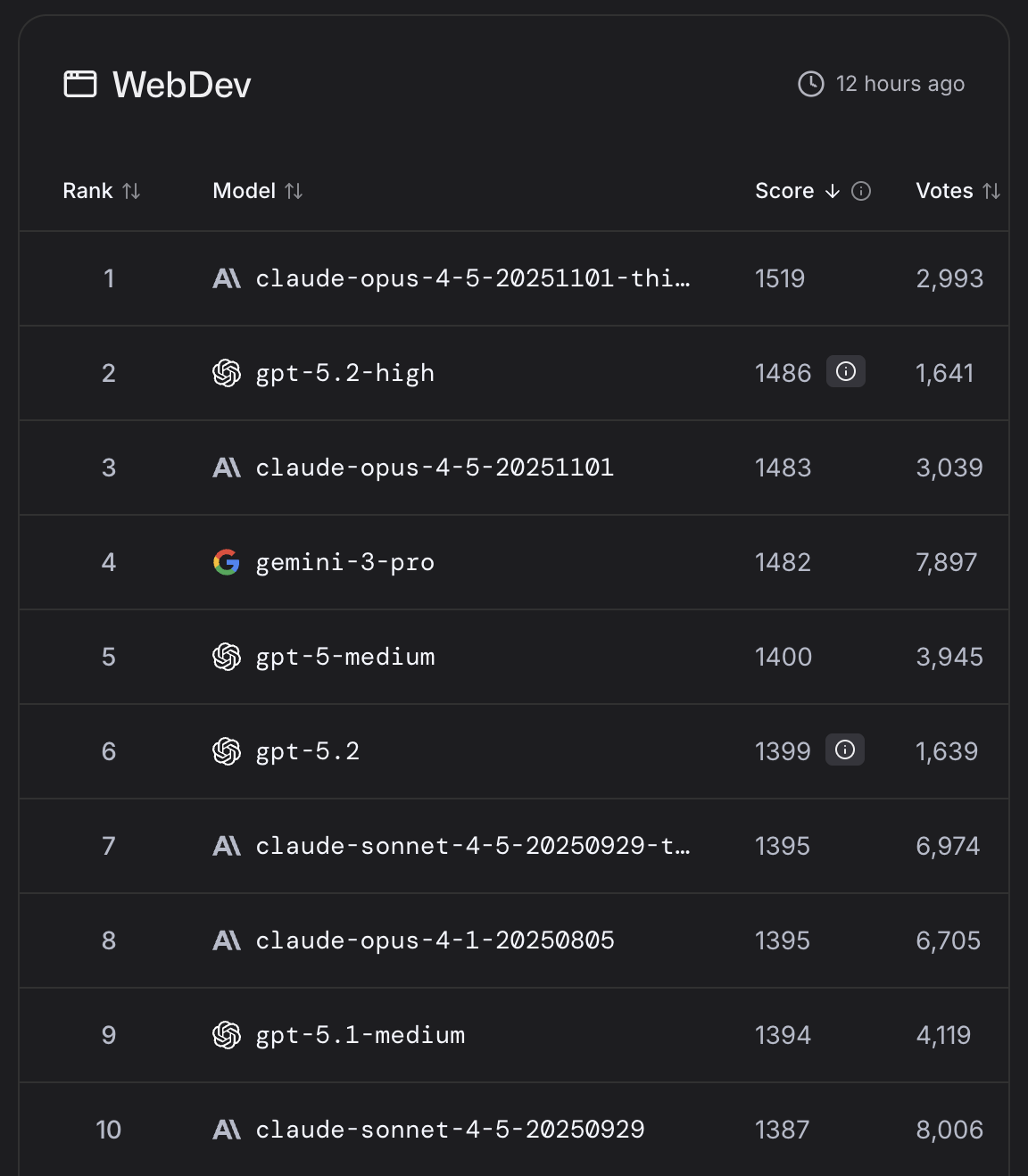
從 Gemini 3 Pro 的衝擊到 GPT-5.2 的誕生
2025 年 11 月 19 日,Google 推出 Gemini 3 Pro,並在多項 Benchmark 測試中超越包括 GPT-5.1 在內的大型 LLM,再次點燃大型模型之間的競爭。根據 SimilarWeb 的數據,Gemini 3 Pro 發布後短短兩週內,ChatGPT 全球日均訪問量便從 2.03 億下滑至 1.91 億,流失約 6% 的使用者。這樣的衝擊使 OpenAI 啟動代號 Code Red 的內部專案,緊急整合資源、調整策略,將重心放回模型的底層效能與思考能力優化,在 12 月 11 日,GPT-5.2 正式登場,作為對 Google 強勢進攻的第一個回應。