什麼是多模態?
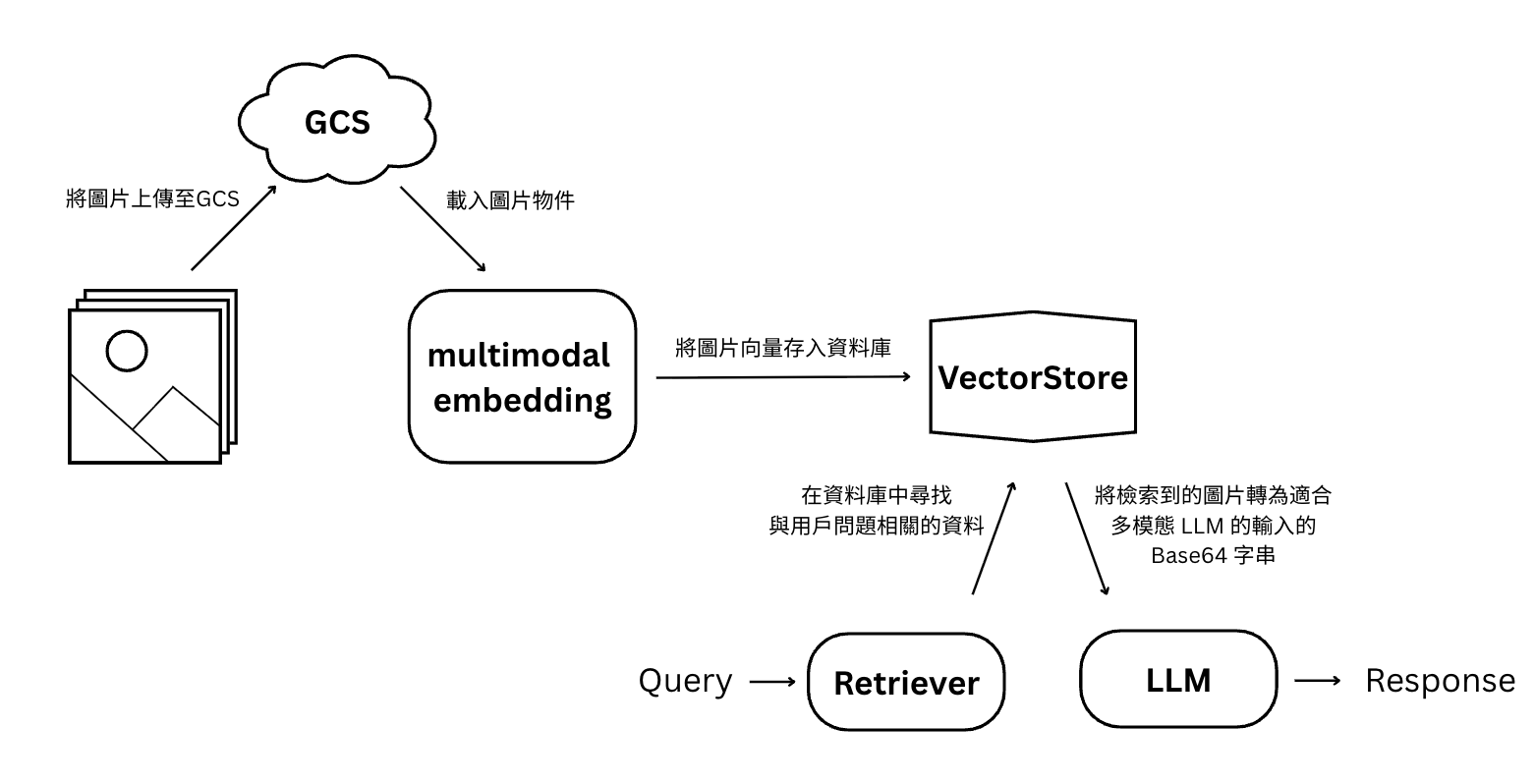
多模態指的是能夠同時處理多種不同形式的資料,例如文字、圖像、影片、音訊等。過去的 AI 模型大多只能處理單一模態的資料,如大型語言模型(LLM)通常僅處理文字資料、卷積神經網路(CNN)模型則是處理影像資料。而近期出現的多模態 AI 模型,能夠整合並理解多種類型資料,讓 AI 模型能對輸入的資訊有更全面的理解。
這背後的關鍵技術之一是多模態嵌入(multimodal embedding)模型。它能將不同類型的資料(如圖片、文字)轉換成相同語意空間和維度的向量,並使這些向量可以互換使用,也就是圖片和文字資料可以在同一個向量空間一起被處理。這讓 AI 模型能夠實現用文字來搜尋圖片,或是用圖片來尋找相關的影片,大幅提升了 AI 模型的應用範圍。